A longstanding problem in the HTTP Archive dataset has been extracting insights from blobs of HTML in BigQuery. For example, take the source code of example.com:
<!doctype html>
<html>
<head>
<title>Example Domain</title>
<meta charset="utf-8" />
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
<style type="text/css">...</style>
</head>
<body>
<div>
<h1>Example Domain</h1>
<p>This domain is for use in illustrative examples in documents. You may use this
domain in literature without prior coordination or asking for permission.</p>
<p><a href="https://www.iana.org/domains/example">More information...</a></p>
</div>
</body>
</html>
Code language: HTML, XML (xml)If you wanted to extract the link text in the last paragraph, you could do something relatively straightforward like this:
// 'More information...'
document.querySelector('p:last-child a').textContent;
Code language: JavaScript (javascript)But in BigQuery, we don’t have the luxury of the document object, querySelector, or textContent.
Instead, we’ve had to resort to unwieldy regular expressions like this:
# 'More information...'
SELECT
REGEXP_EXTRACT(html, r'<p><a[^>]*>([^<]*)</a></p>') AS link_text
FROM
body
Code language: SQL (Structured Query Language) (sql)It looks like it works, but it’s brittle.
- What if there’s text or whitespace between the elements?
- What if there are attributes on the paragraph?
- What if there’s another
p>aelement pair earlier in the page? - What if the page uses uppercase tag names?
It goes on and on.
Using regular expressions for parsing HTML seems like a good idea at first, but it becomes a nightmare as you need to ramp it up to increasingly unpredictable inputs.
To avoid this headache in HTTP Archive analyses, we’ve resorted to custom metrics. These are executed on each page at runtime, and it’s been really effective. It enables us to analyze both the fully rendered page as well as the static HTML. But one big limitation with custom metrics is that they only work at runtime. So if we want to change the code or analyze an older dataset, we’re out of luck.
Cheerio
While looking for a way to implement capo.js in BigQuery to understand how pages in HTTP Archive are ordered, I came across the Cheerio library, which is a jQuery-like interface over an HTML parser.
It works beautifully.
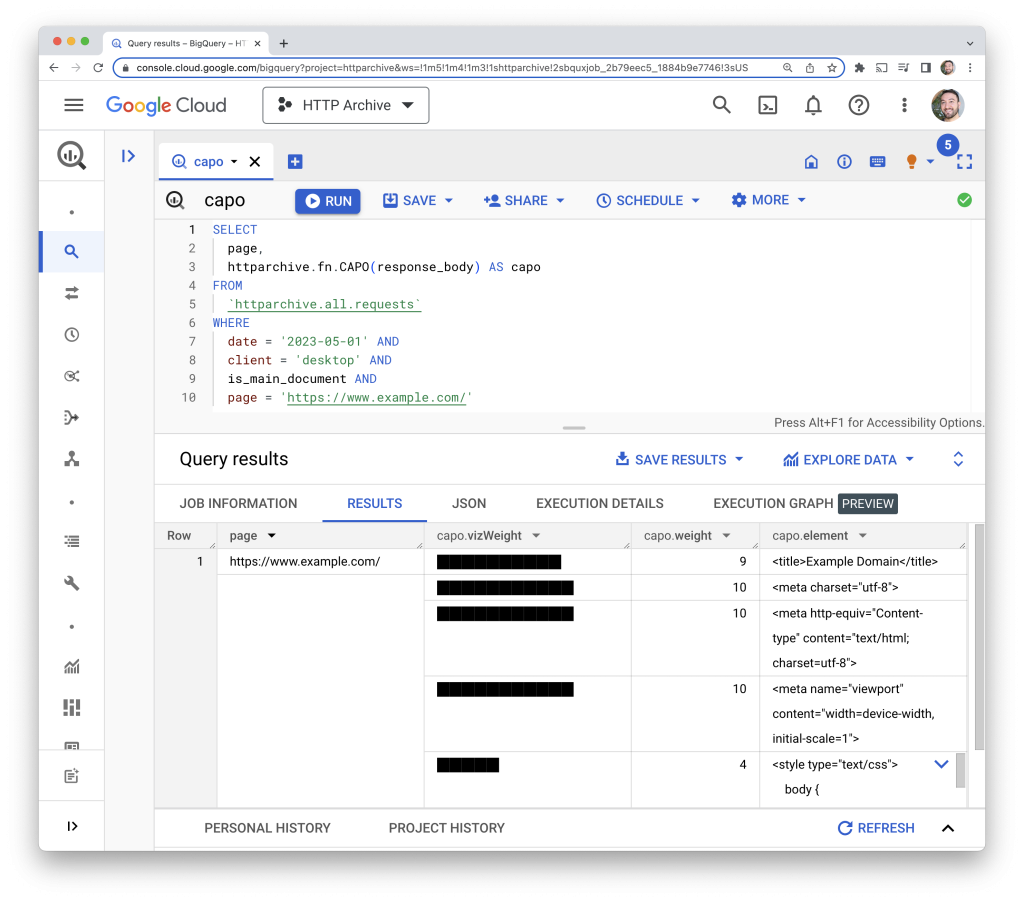
To be able to use Cheerio in BigQuery, I first needed to build a JavaScript binary that I could load into a UDF. The post How To Use NPM Library in Google BigQuery UDF was a big help. I installed the Cheerio library locally and built it into a script with an exposed cheerio global variable using Webpack.
I uploaded the script to HTTP Archive’s Google Cloud Storage bucket. Then in BigQuery, I was able to side-load the script into the UDF with OPTIONS:
OPTIONS (library = 'gs://httparchive/lib/cheerio.js')Code language: SQL (Structured Query Language) (sql)From there, the UDF was able to reference the cheerio object to parse the HTML input and generate the results. You can see it in action at capo.sql.
Querying HTML in BigQuery
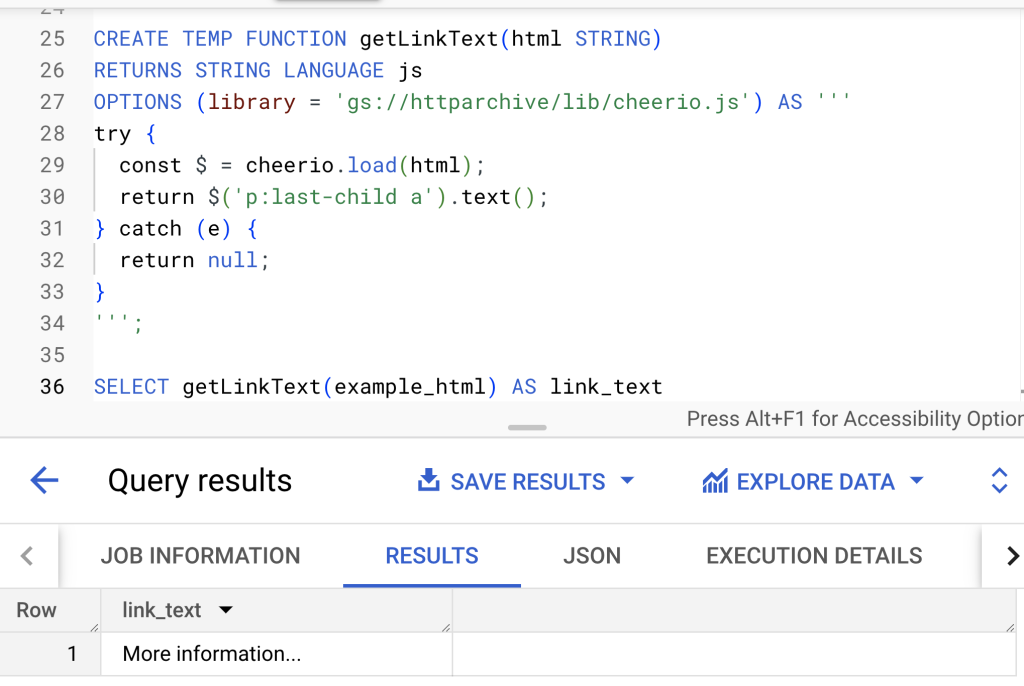
Here’s a full demo of the example.com link text solution in action:
DECLARE example_html STRING;
SET example_html = '''
<!doctype html>
<html>
<head>
<title>Example Domain</title>
<meta charset="utf-8" />
<meta http-equiv="Content-type" content="text/html; charset=utf-8" />
<meta name="viewport" content="width=device-width, initial-scale=1" />
<style type="text/css">...</style>
</head>
<body>
<div>
<h1>Example Domain</h1>
<p>This domain is for use in illustrative examples in documents. You may use this
domain in literature without prior coordination or asking for permission.</p>
<p><a href="https://www.iana.org/domains/example">More information...</a></p>
</div>
</body>
</html>
''';
CREATE TEMP FUNCTION getLinkText(html STRING)
RETURNS STRING LANGUAGE js
OPTIONS (library = 'gs://httparchive/lib/cheerio.js') AS '''
try {
const $ = cheerio.load(html);
return $('p:last-child a').text();
} catch (e) {
return null;
}
''';
SELECT getLinkText(example_html) AS link_text
Code language: SQL (Structured Query Language) (sql)The results show it working as expected:
Limitations

If you try to parse every HTML response body in HTTP Archive, the query will fail.
Fully built, the library is 331 KB. And due to the need for storing the HTML in memory to parse it, it consumes a lot of memory for large blobs.
To minimize the chances of OOM errors and speed up the query, one thing you can do is pare down the HTML to the area of interest using only the most basic regular expressions. Since the capo script is only concerned with the <head> element, I grabbed everything up to the closing </head> tag:
httparchive.fn.CAPO(
REGEXP_EXTRACT(
response_body,
r'(?i)(.*</head>)'
)
)
Code language: SQL (Structured Query Language) (sql)If there are no natural “breakpoints” in the document for your use case, you could also consider restricting the input to a certain character length like WHERE LENGTH(response_body) < 1000. The query will work and it’ll run more quickly, but the results will be biased towards smaller pages.
Also, some documents may not be able to be parsed at all, resulting in exceptions. I added try/catch blocks to the UDF to intercept any exceptions and return null instead.
That also means that your query needs to be able to handle null values instead. For example, to get the first <head> element from the results, I needed to use SAFE_OFFSET instead of plain old OFFSET to avoid breaking the query on null values: elements[SAFE_OFFSET(0)].
Wrapping up
Cheerio is a really powerful new tool in the HTTP Archive toolbox. It unlocks new types of analysis that used to be prohibitively complex. In the capo.sql use case, I was able to extract insights about pages’ <head> elements that would have only been possible with custom metrics on future datasets.
I’m really interested to see what new insights are possible with this approach. Let me know your thoughts in the comments and how you plan to use it.
Leave a Reply